
Flujo multi-agente: ChatGPT, Claude y Hermes Agent
Una semana usando ChatGPT, Claude y Hermes para convertir Forma, TokenMeter, Backend to the Future y el homelab en una línea de montaje más repetible.
La semana en una frase
Esta semana no fue solo de enviar features. Fue de construir la fábrica que las produce.
Trabajé con tres agentes con roles distintos: ChatGPT para producto, arquitectura y backlog; Claude para discusión técnica, implementación y revisión de decisiones; Hermes para operar el sistema real: repos, Docker, Jira, GitHub, nginx, Grafana, Home Assistant y despliegues.
Lo interesante no es que cada agente hiciera “cosas de IA”. Lo interesante es que, cuando todos comparten contexto —Jira, specs, ADRs, skills, repositorios y smoke tests— empiezan a parecer menos chats sueltos y más un pequeño equipo de software.
El producto dejó de ser una idea
El centro de la semana fue Forma, una aplicación de fitness que vive en forma.diegobarrioh.dev y en Jira bajo el proyecto FOR.
ChatGPT ayudó sobre todo a convertir la idea en producto: epics, módulos, estructura funcional, backlog y criterios de aceptación. La conversación no iba tanto de escribir código como de eliminar ambigüedad. ¿Qué módulos existen? ¿Qué significa Body Composition? ¿Qué entra en Training? ¿Qué historias pertenecen a Foundation? ¿Qué tiene que estar explícito para que otro agente pueda implementar sin preguntar cada dos minutos?
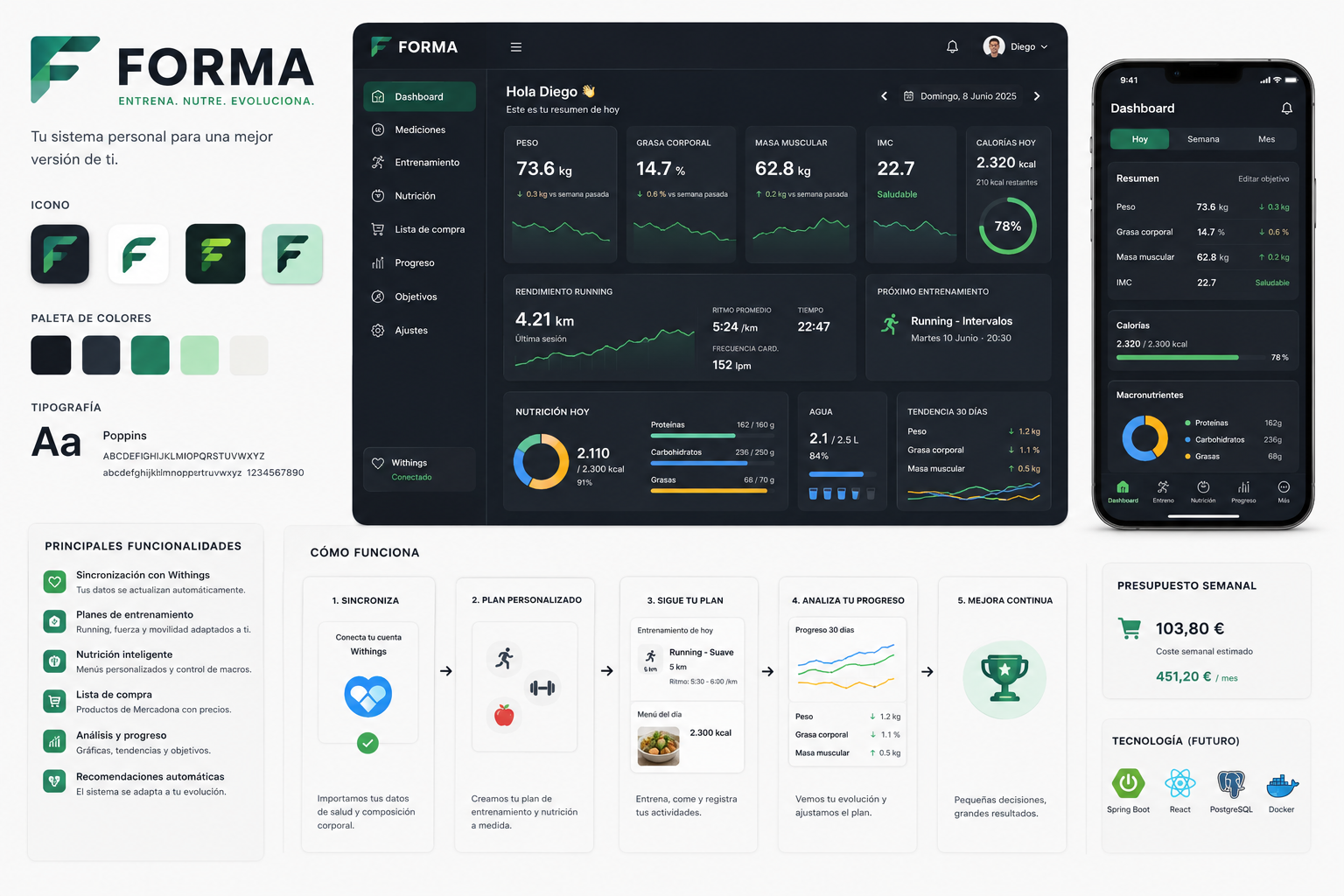
Ese mockup fue más útil de lo que parece. No era solo una imagen bonita: era una forma de fijar el lenguaje visual, los módulos principales y la sensación de producto antes de pedir a ningún agente que escribiera código. Cuando el equipo de IA tiene una referencia visual compartida, baja mucho la ambigüedad.
El resultado fue que Forma empezó a tener una forma reconocible:
- base de aplicación;
- dashboard;
- módulos de entrenamiento, nutrición, composición corporal y progreso;
- configuración y navegación;
- base de datos PostgreSQL;
- integración de servicios externos prevista;
- backlog estructurado por epics;
- historias con objetivo, valor, especificación, notas técnicas, criterios de aceptación y Definition of Done.
La lección fue bastante clara: los modelos no suelen atascarse por falta de capacidad para escribir código. Se atascan por requisitos ambiguos. Cuanto más aburrida y explícita es la especificación, más consistente es la implementación.
Claude y la idea de construir la fábrica
Claude puso el foco en algo que esta semana se volvió central: el producto visible no era lo único importante. La parte valiosa era la línea de montaje.
Forma arrancó con FOR-93, una historia pensada para validar el workflow de desarrollo asistido por IA. El objetivo no era todavía construir la feature más vistosa, sino demostrar que una historia de Jira podía convertirse en una PR revisable siguiendo un camino repetible:
- leer
AGENTS.md; - leer la historia y sus specs;
- leer ADRs y documentación relacionada;
- crear rama;
- implementar;
- verificar;
- commitear;
- abrir PR;
- dejar evidencia.
El ensayo con FOR-89, la documentación de desarrollo local, sirvió para comprobar que el método aguantaba. Después el bucle empezó a repetirse: historia de Jira, specs, PR, merge, limpieza de main y ramas huérfanas, siguiente historia.
Por el camino fueron cayendo cimientos:
- FOR-80: esqueleto backend con Spring Boot, Java 21 y Gradle;
- FOR-81: esqueleto frontend con Vite, React y TypeScript;
- FOR-82: entorno local con Docker Compose;
- FOR-83 a FOR-88: base de API, testing y estructura técnica;
- FOR-90: configuración de secretos y fail-fast para producción.
Lo más interesante apareció con FOR-94. Esa historia no encajaba en el molde de “implementa una historia a partir de specs”, porque precisamente consistía en generar specs para una épica. La primera tentación fue meter un caso especial en el workflow existente. La solución buena fue otra: separar responsabilidades.
Una herramienta genera specs de épicas. Otra implementa historias a partir de specs. Esa costura limpia vale más que un parche rápido.
Hermes: de comandos sueltos a memoria operacional
Mientras ChatGPT y Claude trabajaban sobre producto, specs y arquitectura, Hermes estuvo en el mundo físico: servidores, contenedores, rutas públicas, logs, health checks y dashboards.
Primero habilitamos forma.diegobarrioh.dev en el nginx público de red.local, con certificado SSL y reverse proxy hacia el frontend en Omarchy. La convención de puertos quedó explícita:
- Akademia usa
3000; - TokenMeter usa
3001; - Forma usa
3002; - el siguiente proyecto debería empezar proponiendo
3003.
Ese procedimiento acabó convertido en la skill nginx-public-site-enable. No es solo una nota: obliga a descubrir sites existentes, revisar puertos, proponer el siguiente, crear HTTP primero, emitir certificado, escribir HTTPS, validar nginx -t, recargar nginx y hacer smoke tests.
Después creamos forma-ops, la skill equivalente a tokenmeter-ops y akademia-ops. Forma quedó tratada como un proyecto operativo de primera clase: repo en ~/code/forma, Jira FOR, URL pública, for up, for down, Docker Compose, smoke tests, logs y PR evidence.
La primera validación real fue imperfecta, y por eso fue útil. Compose todavía publicaba puertos temporales que no encajaban del todo con el diseño final, así que levantamos Forma con overrides seguros:
FRONTEND_PORT=3002 BACKEND_PORT=18080 POSTGRES_PORT=15432
Y verificamos lo importante: frontend local, contenedores healthy, actuator backend, URL pública y estado de la PR. Esa es la diferencia entre “Docker arranca” y “esta PR está operativamente validada”.
Al cerrar la semana, Forma ya no era solo backlog y arquitectura. Todavía es un esqueleto, y la propia pantalla lo dice: el resumen diario se construirá cuando existan fuentes de datos. Pero ya hay una app real servida en producción, con navegación, layout, tema visual y módulos preparados para que las próximas historias empiecen a llenar producto, no infraestructura.
TokenMeter: cuando los tests protegen el bug
TokenMeter dejó la lección técnica más afilada de la semana.
GA4 decía que no recibía datos en tokenmeter.backendtothefuture.com. Lo raro era que gtag.js cargaba bien, el measurement ID era correcto y todo parecía razonable. El problema estaba en una sola línea: el shim de gtag estaba escrito como una arrow function que empujaba un array plano al dataLayer.
El snippet oficial de Google no hace eso. Usa una función normal y empuja el objeto arguments nativo. gtag.js espera esa forma concreta. El array plano se ignora en silencio. No hay error bonito. No hay consola roja. Simplemente no sale ninguna petición real de analytics.
Lo peor: los tests estaban en verde porque validaban la forma bugueada. Es decir, no estaban detectando el problema; lo estaban blindando.
La corrección real no fue solo cambiar una línea. Fue cambiar el contrato de los tests:
- validar la forma real que espera
gtag.js; - añadir una regresión para que ninguna entrada del
dataLayersea un array plano; - comprobar analytics con Network y datos reales, no solo con build verde.
Es una buena lección para cualquier workflow con agentes: un test que codifica el bug es peor que no tener test. Da confianza justo donde no debería.
Datos frescos, logs y observabilidad
También hubo trabajo en TokenMeter alrededor de datos y observabilidad.
La sección “Popular esta semana” estaba usando la Search API de GitHub de una forma que devolvía repos con muchas estrellas absolutas, no necesariamente tendencia real. El resultado era una lista demasiado estable, casi congelada. La solución fue moverse hacia un adaptador que lee trending real y deja la Search API como fallback.
Además aterrizaron mejoras relacionadas con TKM-72 y logs del backend para el stack central Promtail → Loki → Grafana en red.local.
El patrón se repite: no basta con tener una feature. Hay que poder observarla, entenderla y cambiar su fuente de datos sin romper todo.
Backend to the Future y la parte invisible de publicar
Backend to the Future también apareció en el resumen de la semana, aunque de forma menos vistosa.
Había trabajo pendiente de indexación en Google. Algunas páginas no estaban entrando como deberían, y el diagnóstico se amplió para incluir también el subdominio de TokenMeter, con su propio sitemap y su propio analytics.
Publicar contenido no termina en escribir Markdown y hacer deploy. También hay que pensar en cómo Google descubre las páginas, qué sitemap ve, qué propiedad de Search Console aplica y si el analytics mide realmente lo que creemos que mide.
Es otra versión del mismo tema: el valor está en el sistema alrededor del contenido.
Home Assistant, Grafana y el homelab real
Hermes también siguió operando la casa.
En Home Assistant ajustamos dashboards: chips de Mushroom con colores por temperatura, tarjetas más limpias, fondos oscuros, gráficas mini-graph-card más finas y una integración de Trakt que aclaró una diferencia importante: los sensores no son listas manuales, son vistas derivadas de la cuenta de Trakt.
En Grafana investigamos una alerta de muchos 429 en audio.diegobarrioh.dev. La conclusión fue que Audiobookshelf estaba bien; el ruido venía de un scanner externo buscando .env, .git, WordPress y rutas típicas vulnerables. Nginx estaba haciendo lo correcto: rate limiting.
También diagnosticamos un cuelgue de Omarchy. No había OOM, ni disco lleno, ni fallo grave de filesystem. Sí había un segfault de Hyprland en libaquamarine.so.0.10.0, seguido de errores de upower. La conclusión fue más precisa que “el ordenador va mal”: probablemente cayó la sesión gráfica, no todo el sistema.
Ese tipo de distinción importa. Reiniciar todo arregla el síntoma, pero entender qué se cayó permite operar mejor la siguiente vez.
Seguridad pequeña: el actuator público
Cerramos la semana con una comprobación sencilla pero importante: si los endpoints de actuator estaban disponibles desde fuera.
Probamos rutas como:
https://forma.diegobarrioh.dev/actuator/health
https://akademia.diegobarrioh.dev/actuator/health
https://tokenmeter.backendtothefuture.com/actuator/health
Todas devolvían 200, pero no era Spring Actuator. Era el index.html del frontend por el fallback de la SPA.
La lección es buena: en una SPA, un 200 no significa necesariamente que el endpoint exista. Puede significar que nginx está sirviendo el frontend para cualquier ruta desconocida.
En este caso, la respuesta correcta fue que no parecía haber actuator público real. Y eso es justo lo que queremos.
El equipo de tres agentes
Visto en conjunto, el reparto de trabajo fue bastante natural:
- ChatGPT ayudó a pensar el producto: visión, módulos, backlog, roadmap, arquitectura y ambigüedad de requisitos.
- Claude ayudó a convertir ese trabajo en una fábrica de desarrollo: workflows, specs, historias, PRs, tests y decisiones técnicas.
- Hermes operó el mundo real: repos, contenedores, nginx, certificados, GitHub, Jira, Grafana, Home Assistant y smoke tests.
La productividad no vino de que un modelo fuese mágicamente mejor que otro. Vino de asignar roles y compartir contexto.
El repositorio, Jira, las specs, los ADRs y las skills se convirtieron en la fuente común de verdad. Cuanto mejor está esa fuente, menos depende el resultado de la memoria de una conversación concreta.
Lowlights
No todo salió limpio.
El tokenizer de DeepSeek en TokenMeter mostró una fragilidad clásica de dependencias nativas: algo que funciona en un host puede romper en otro por carga de librerías. El bug de GA4 llevaba tiempo vivo porque la suite de tests estaba protegiendo el comportamiento incorrecto. Y Forma avanzó mucho, pero todavía en modo cimientos: backend, frontend, Docker, testing, configuración y workflow. Las features visibles de fitness empiezan ahora.
También hay una tensión clara: cuanto más rápido se vuelve el pipeline, más importante es que el pipeline tenga límites. Si una skill intenta hacerlo todo, acaba llena de casos especiales. Si los tests validan lo que escribió el agente en vez del contrato externo, dan una falsa sensación de seguridad.
Mi conclusión
Esta semana confirmé una idea que cada vez me parece más importante: trabajar con agentes no va de pedir código más rápido. Va de mover la ingeniería hacia arriba.
El cuello de botella ya no es solo escribir software. Es describirlo bien, estructurar el backlog, definir contratos, crear workflows, validar con evidencias y dejar procedimientos reutilizables.
La fábrica importa tanto como el producto.
Forma todavía no es una aplicación completa de fitness. TokenMeter todavía tiene deuda técnica. Backend to the Future todavía tiene trabajo de indexación. El homelab sigue teniendo piezas viejas y frágiles.
Pero esta semana pasó algo importante: ChatGPT, Claude y Hermes no trabajaron como tres chats aislados. Trabajaron alrededor de una misma línea de montaje.
Y cuando eso ocurre, cada sesión deja de ser un experimento y empieza a convertirse en capacidad acumulada.