De rediseño a producción: la semana en que todo empezó a medirse
Resumen del 15 al 21 de junio: analytics con consentimiento RGPD, SEO para indexar, una guerra contra los datos ruidosos en TokenMeter, y la idea que conecta todo — no puedes mejorar lo que no puedes ver.
El finde como banco de pruebas
La semana pasada fue rediseño: design system nuevo, blog bilingüe, un CV que por fin dice la verdad. Esta semana fue la continuación poco glamurosa pero importante — coger esos sitios rediseñados y hacerlos reales: medidos, indexados, con consentimiento y listos para producción. Dos repos cargaron la semana, Backend to the Future y TokenMeter, y al sentarme el domingo la misma palabra aparecía en los dos: instrumentación.
Esta entrada cruza dos miradas: lo que se envió de verdad, y el porqué de fondo — la idea de que el reto interesante de la IA ya no es el modelo, sino todo lo que necesitas para verlo funcionar. No todo brilló. También hubo cosas que se rompieron.
Highlights — lo que se envió
Backend to the Future pasó de "parece terminado" a "se comporta como producción".
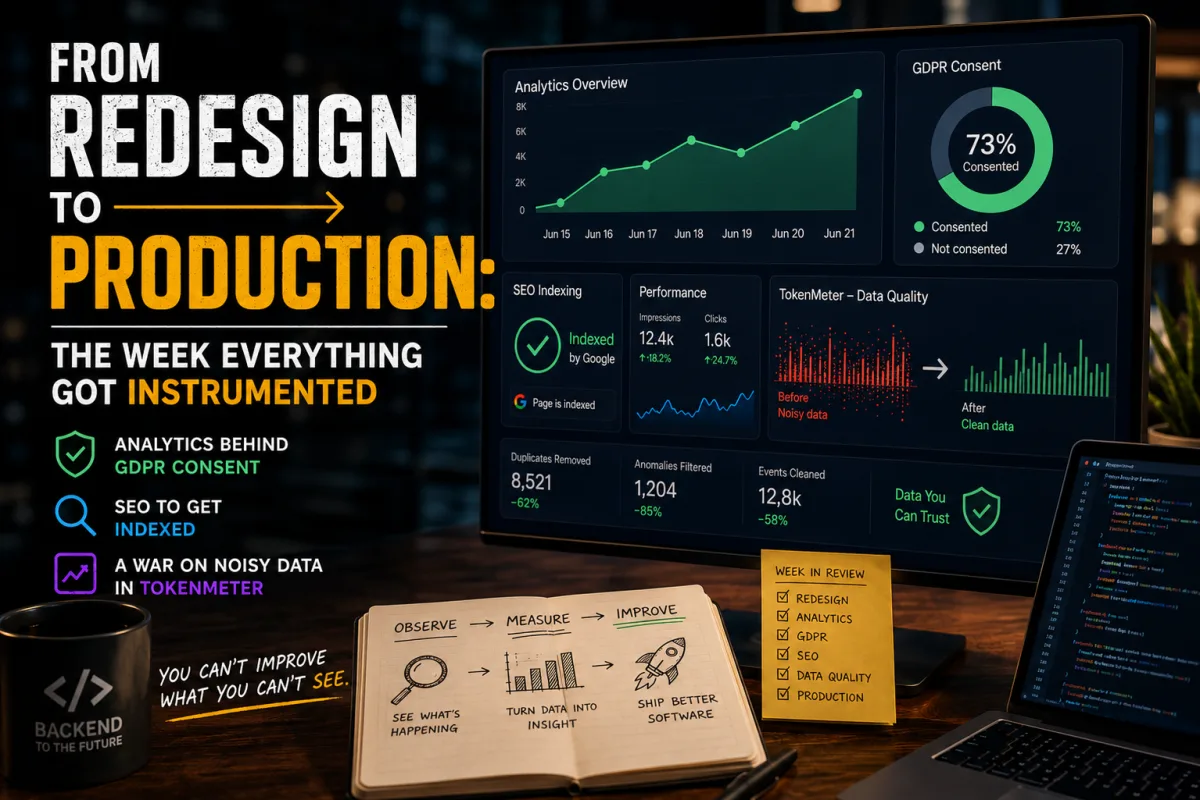
Primero, analytics. Cableé GA4 con @next/third-parties, pero lo interesante no fue la etiqueta — fue la restricción del RGPD. Vivir en Alicante significa que gtag no puede dispararse antes del consentimiento explícito, así que construí un banner que bloquea Google Analytics por completo: cero tracking hasta que el usuario acepta. Lo implementé contra un G-XXXXXXXX de placeholder, metí la propiedad real G-0ZG2B4VPF8 cuando creé la aplicación correcta en GA4, lo levanté en dev para ver el banner, desplegué y confirmé mi propia visita apareciendo en GA4 realtime. Bucle de medición cerrado.
Luego audité ese banner contra el RGPD en serio y encontré tres fallos — los tres corregidos en fix/cookie-consent-rgpd: no había forma de retirar el consentimiento (Artículo 7.3), no había información ni enlace a política, y lo peor, Google Fonts cargaba desde el CDN de Google antes del consentimiento, filtrando la IP del visitante. Auto-hospedar las fuentes cerró la fuga. Es el tipo de trabajo que nadie ve pero que un regulador sí.
Después, hacerse indexar. Con el dominio ya verificado en Search Console, envié los cimientos SEO en feat/seo-indexing: sitemap, robots y metadataBase. Y la capa rica — datos estructurados JSON-LD, una imagen OG para las vistas previas en redes, y URLs por post para que cada artículo sea su propia página indexable en vez de un ancla. Reenvié el sitemap y solicité indexación del primer recap. Ahora a esperar a Google.
Por último, pulido del propio blog: el margen superior pesaba demasiado en web y móvil, así que lo recorté a la mitad. Y añadí imágenes — miniatura en cada tarjeta y cabecera de portada dentro de cada post. Eso costó iteración: la imagen a la izquierda quedaba mal en móvil, así que la reapilé con la imagen arriba y el texto debajo. Salió como PR #10, mergeada y desplegada.
Los deploys, por cierto, siguen siendo satisfactoriamente de baja tecnología: ./deploy.sh hace npm run build y sincroniza out/ directo al servidor de producción. Sin teatro de pipelines.
TokenMeter fue el trabajo más pesado: dos sprints y una guerra contra los datos ruidosos.
Corrí un sprint de Jira completo, lo cerré, abrí otro y también lo cerré. Empecé analizando el tablero para ver qué quedaba de verdad, e implementé los tickets en orden — TKM-54, luego TKM-57 dentro de la misma PR por estar relacionados, con smoke tests manuales en el equipo de pruebas entre medias. Cuando los tickets de UX restantes dejaron de tener sentido — la fase de análisis ya se veía sólida —, tomé la decisión de cerrarlos en vez de construir cosas que nadie necesitaba, y actualicé el README con el estado real de la epic. Luego sprint nuevo: TKM-62, TKM-65, TKM-63 y por fin TKM-64 para cerrarlo.
El hilo más interesante fue la guerra contra el ruido. TokenMeter descargaba todas las variantes de modelo de LiteLLM — cada snapshot con fecha, cada modelo deprecado, cada gpt-4-0314 y claude-3-...-20240307. La tabla de precios se ahogaba en versiones que nadie usa. Así que la filtré a modelos canónicos y activos: fuera las variantes con fecha, fuera los deprecados, y fuera los niveles "pro" de OpenAI cuyo precio extremo distorsionaba los rankings sin reflejar el uso normal. Una comparativa de precios solo sirve si las filas son las que de verdad elegirías.
Ya puestos en la tabla, hice las cabeceras de las columnas input/output tokens ordenables — clic para ordenar ascendente/descendente con su flechita arriba/abajo. Eso introdujo una regresión donde el orden se perdía tras la limpieza de datos, que tuve que perseguir y arreglar. Mereció la pena: una tabla de precios que puedes ordenar por coste es justo el punto.
También arreglé un bug real: tras analizar un repo, la tarjeta de "popular esta semana" en la home no lo marcaba como analizado. Analicé TheAlgorithms/Python a mano y se quedaba sin marcar — un problema de estado que no se refresca, que tracé y corregí, confirmando luego que la tarjeta se actualiza bien.
Lancé /code-review ultra sobre la PR #42 para una pasada multi-agente profunda antes de mergear, añadí GA4 a TokenMeter también, y durante la semana fui mergeando PRs de forma constante, pasando cada Jira a done según aterrizaba.
La pieza que mira hacia delante: pregunté qué tres mejoras necesita TokenMeter de verdad, y convertí la respuesta en una epic más tres historias. La principal es el conteo local de tokens — estimar el coste de los modelos con tokenizers locales en vez de depender de las APIs de los proveedores, llamando a la API solo como fallback. Eso es TokenMeter comiendo de su propia comida: si el producto va de entender la economía de los tokens, debería contarlos él mismo.
El detalle que vale la pena enseñar
El consentimiento es donde la mayoría de las integraciones de analytics se equivocan sin saberlo. Es fácil pensar que el RGPD se cumple poniendo un banner y dejando de cargar gtag hasta el clic. Pero el agujero real estaba más abajo: Google Fonts cargando desde el CDN de Google antes del consentimiento ya filtraba la IP del visitante a Google, banner o no. Cumplir de verdad significó auto-hospedar las fuentes, no solo gobernar la etiqueta de analytics. La lección: el consentimiento no es una capa que pones encima — es auditar cada petición de red que sale antes de que el usuario diga que sí.
El hilo que conecta todo
Visto en frío, la semana no fueron dos proyectos sueltos — fue la misma disciplina aplicada dos veces. Los dos sitios recibieron analytics tras un consentimiento correcto. A los dos se les limpiaron datos y presentación. Y la razón de existir de TokenMeter — medir el coste oculto de la IA — es el mismo instinto que aplicaba a mis propios sitios: no puedes mejorar lo que no puedes ver. La semana pasada hice que las cosas se vieran bien. Esta semana hice que fueran observables.
Y esa idea es más grande que mis repos. Cada vez me interesa menos consumir productos de IA y más entender cómo funcionan por dentro. Los modelos impresionan, pero el ecosistema alrededor — tokenización, observabilidad, tracking de coste, tooling, infraestructura — es donde sigue viviendo casi toda la ingeniería. La oportunidad no es solo construir mejores modelos; es construir mejor instrumentación alrededor de ellos. Lo que TokenMeter persigue con la tokenización local — dejar de tratar el conteo de tokens como una caja negra del proveedor — es exactamente eso.
Lowlights
No todo fue fino. El trabajo de columnas ordenables rompió su propio ordenamiento tras la limpieza de la lista de modelos — un recordatorio de que dos cambios tocando la misma tabla colisionan si no piensas el orden. La tarjeta de "popular esta semana" fallando en silencio al marcar repos analizados era ese tipo de bug de estado obsoleto que pasa un vistazo rápido y solo aparece cuando usas la función como un usuario de verdad. Y el SEO no tiene final satisfactorio: hice todo bien — sitemap, datos estructurados, solicitudes de indexación — y el único estado honesto es "enviado, ahora esperamos". La indexación es la única parte de enviar de la que no puedes salir mergeando.
Conclusiones
- El analytics es lo fácil; el consentimiento bien hecho (retirada, política, sin fugas de IP pre-consentimiento) es el trabajo de verdad.
- Una herramienta de comparación vale lo que valen sus filas — recorta datos deprecados y atípicos antes de que distorsionen la señal.
- Dos cambios sobre el mismo componente pelearán; la limpieza y las funciones nuevas necesitan un plan de orden.
- Los bugs de estado obsoleto sobreviven a la revisión de código y mueren bajo uso real — ejercita la función como un usuario.
- El SEO se envía en el reloj de Google, no en el tuyo; hazlo bien y espera.
- El mejor instinto de producto es el auto-aplicado: instrumenté mis sitios con el mismo reflejo de "mídelo" sobre el que está construido TokenMeter.
Qué sigue
Los dos sitios están ya en producción con sus bucles de medición corriendo, así que el siguiente paso es actuar sobre lo que me cuenten — leer los datos de GA4, ver aterrizar la indexación, y dejar que el uso real guíe la hoja de ruta. En TokenMeter, la epic del tokenizer local es la grande: que la herramienta calcule el coste de los tokens ella misma en vez de fiarse de las APIs de los proveedores. El tema se mantiene desde la semana pasada — local-first, medido, asistido por IA — y ahora hay datos reales volviendo para confirmar o desmentir cada decisión.